Two Independent Samples
We often have two independent random samples instead of paired samples, and want to make inferences about the two populations from which the samples are drawn.
$$ \begin{aligned} &\text{Sample 1}: x_1, x_2, \cdots, x_m \\ &\text{Sample 2}: y_1, y_2, \cdots, y_n \end{aligned} $$
for convenience and without loss of generality, we assume $n \geq m$. What can we say about the populations from which these samples were drawn? We may want to ask about the centrality or location of the population distributions. In particular, our usual question is are these the same for the two. More generally, do the population distributions coincide, or do they differ by a shift in location? We’re often interested in whether one population tends to yield larger values than the other, or do they tend to yield similar values.
The most common approach is a modification of Wilcoxon for two independent samples. It has a different formulation called the Mann-Whitney test. Usually they’re talked together as the WMW test.
The Mann-Whitney test
There are three different (but essentially equivalent) ways of formulating the hypotheses of interest:
- In terms of the underlying population distributions:
$$ \begin{aligned} &H_0: F(z) = G(z) &&\text{for all } z \\ \text{vs. } &H_1: F(z) \neq G(z) && \text{for all } z \end{aligned} $$
where $F(\cdot)$ is the distribution corresponding to $X$ (first sample) and $G(\cdot)$ is the distribution corresponding to $Y$ (both are CDFs).
- In terms of means / expectations:
$$ \begin{aligned} &H_0: E(X) = E(Y) \\ \text{vs. } &H_1: E(X) \neq E(Y) \end{aligned} $$
Here we can use WMW as a test of mean comparison.
- In terms of probabilities:
$$ \begin{aligned} &H_0: P(X > Y) = P(X < Y) \\ \text{vs. } &H_1: P(X > Y) \neq P(X < Y) \end{aligned} $$
Usually we see the hypotheses in the $2^{nd}$ or $3^{rd}$ form. One-sided questions could also be of interest:
$$ \begin{aligned} &H_0: F(z) = G(z) &&\text{for all } z \\ \text{vs. } &H_1: F(z) > G(z) && \text{for some } z \\ \text{or vs. } &H_1: E(X) < E(Y) \\ \text{or vs. } &H_1: P(X > Y ) < P(X < Y) \end{aligned} $$
Here all the alternatives are for $X$ tend to be smaller than $Y$.
Test statistic formulations
After forming the hypothesis, we may define our test statistic as:
$$ S_m = \sum\limits_{i=1}^m {R(x_i)} $$
which is the sum of the ranks from sample 1, and $R(x_i)$ is the rank from the combined sample. Equivalently, we can use $S_n$ - sum of ranks from sample $2$. From this we can derive the Mann-Whitney formulation:
$$ \begin{gather*} U_m = S_m - \frac{1}{2}m(m+1) \\ U_n = S_n - \frac{1}{2}n(n+1) \end{gather*} $$
There’s equivalent information in the two statistics, and we can easily derive $U_m = mn - U_n$. This test statistic can be computed without combining the samples, and without using ranks. Consider the following example: we have time to complete a set of calculations in minutes using two different types of calculator. Is there a difference between the two types?
| Group A | 23 | 18 | 17 | 25 | 22 | 19 | 31 | 26 | 29 | 33 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group B | 21 | 28 | 32 | 30 | 41 | 24 | 35 | 34 | 27 | 39 | 36 |
In a Wilcoxon test, we combine the two samples and rank them together:
$$ \begin{gather*} 17 && 18 && 19 && 21^* && 22 && 23 && 24^\\ 25 && 26 && 27^ && 28^* && 29 && 30^* && 31 \\ 32^* && 33 && 34^* && 35^&& 36^ && 39^* && 41^* \end{gather*} $$
The ones marked with $\ast$ are from group B. In our case, $m + n = 21$:
$$ \begin{gather*} S_m = 1 + 2 + 3 + 5 + 6 + 8 + 9 + 12 + 14 + 16 = 76 \\ S_m + S_n = \frac{1}{2} \times 21 \times 22 = 231 \\ S_n = 231 - 76 = 155 \end{gather*} $$
In the Mann-Whitney test, we order the two groups separately:
| Group A | 17 | 18 | 19 | 22 | 23 | 25 | 26 | 29 | 31 | 33 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Group B | 21 | 24 | 27 | 28 | 30 | 32 | 34 | 35 | 36 | 39 | 41 |
We go through each observation in sample A, and count how many observations in sample B are greater than the observation from A. In other words, we count up the exceedances:
$$ 11 + 11 + 11 + 10 + 10 + 9 + 9 + 7 + 6 + 5 = 89 = U_n $$
The Wilcoxon is an extension of the one-sample test, and the Mann-Whitney counts exceedances of one sample relative to the other. The two are equivalent in terms of information about the samples , as shown by the formulations. We can easily convert the values of one test to another.
Other extensions
Other aspects of the one-sample situation extend in a relatively straightforward way to the two-sample case. For example, getting confidence intervals for the “shift” uses a similar idea to the Walsh average approach from the one-sample test, but using $x_i - y_i$:
| 17 | 18 | 19 | $\cdots$ | 29 | 31 | 33 | |
|---|---|---|---|---|---|---|---|
| 21 | -4 | -3 | -2 | $\cdots$ | 8 | 10 | 12 |
| 24 | -7 | -6 | -5 | $\cdots$ | 5 | 7 | 9 |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\ddots$ | $\vdots$ | $\vdots$ | $\vdots$ |
| 39 | -22 | -21 | -20 | $\cdots$ | -10 | -8 | -6 |
| 41 | -24 | -23 | -22 | $\cdots$ | -12 | -10 | -8 |
To get critical values from the table, count from most negative up and count from most positive down. The point estimator for the difference, the Hodges-Lehmann estimator, is the median of the differences.
Also as before, we can use a normal approximation when $m, n$ are reasonably large (or in the case of ties).
$$ \begin{aligned} \text{Wilcoxon:} && E(S_m) &= \frac{1}{2}m(m+n+1) \\ && Var(S_m) &= \frac{1}{12}mn(m+n+1) \\ \text{Mann-Whitney:} && E(U_m) &= \frac{1}{2}mn \\ && Var(U_m) &= \frac{1}{12}mn(m+n+1) \end{aligned} $$
With ties, we make our standard modifications. For the Wilcoxon, we use mid-ranks as before. For the Mann-Whitney, ties from one sample to the other (i.e. $x_i = y_i$ for some $i, j$) counts as $\frac{1}{2}$ in our calculation of $U_m$.
Another thing we can do is to use a normal approximation with the score representation. Let $T$ be the sum of the scores test statistic ($S_m$ or $U_m$) based on ranks or tied ranks. The score for observation $i$ is $S_i$. Then
$$ \begin{gather*} E(T) = \frac{m}{m+n}\sum\limits_{j=1}^{m+n}{S_j} \\ Var(T) = \frac{mn}{(m+n)(m+n-1)}\left[\sum\limits_{j=1}^{m+n}{S_j^2} - \frac{1}{m+n}\left(\sum\limits_{j=1}^{m+n}{S_j}\right)^2\right] \end{gather*} $$
Implementation in R
In R, wilcox.test handles all 3 cases (one sample, paired samples, two independent samples):
- One sample:
wilcox.test(x) - Paired samples:
wilcox.test(x, y, paired = T)xandyshould be two data vectors of the same length
- Independent samples:
wilcox.test(x, y)xandyare two data vectors of possibly different lengthspaired = Fby default
We can get confidence intervals for all 3 cases by setting the parameter conf.int = T and conf.level to a desired value.
The median test
The median test is a simple “quick and dirty” method which is neither very efficient nor robust. The test asks a very specific question: location (median) shift.
Here’s the basic setup. Suppose we have two samples of independent observations of sizes $m$ and $n$. They come from distributions that differ, if at all, only by a shift of location.
$$ \begin{aligned} F(x) &\rightarrow \text{population CDF for the first sample} \\ G(y) &\rightarrow \text{population CDF for the second sample} \end{aligned} $$
The general idea of shifting would be
$$ G(y) = F(x - \theta) $$
Under $H_0$, $\theta = 0 \Rightarrow$ no shift, which means there’s a common median. The sample number of observations above the common median $M$ is $B(n+m, 0.5)$.
Example: Suppose two different methods of growing corn were randomly assigned to number of different plots of land, and the yield per acre was computed for each plot.
| Method 1 ($m=9$) | 83 | 91 | 94 | 89 | 89 | 96 | 91 | 92 | 90 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Method 2 ($n=10$) | 91 | 90 | 81 | 83 | 84 | 83 | 88 | 91 | 89 | 84 |
The common median of the combined samples $M = 89$, and this is a point estimate for the joint median in the population under $H_0$. We arrange the data in a $2 \times 2$ contingency table:
| Method 1 | Method 2 | ||
|---|---|---|---|
| $>89$ | 6 | 3 | 9 |
| $\leq 89^\ast$ | 3 | 7 | 10 |
| 9 | 10 | 19 |
The third row, or the column margins, is fixed by design ($9$ and $10$). The row margins are fixed by the definition of median. With the margins fixed, if we know one value in the table, we can fill in the other three values.
Note that different approaches are possible, for example the book would drop the values exactly equal to $M$, which yields
Method 1 Method 2 $>89$ 6 3 9 $\leq 89^\ast$ 1 5 6 7 8 15
The most common analysis approach is the Fisher's exact test. The idea is to consider all tables that are “as or more extreme than” the observed, consistent with the fixed margins.
For example, if the $(1, 1)$ cell happened to be 4 instead of 6:
| Method 1 | Method 2 | ||
|---|---|---|---|
| $>89$ | 4 | 5 | 9 |
| $\leq 89^\ast$ | 5 | 5 | 10 |
| 9 | 10 | 19 |
we get a more balanced table than the observed one so it’s less extreme, making it more favorable to $H_0$. We get a more extreme table (evidence against $H_0$) if the $(1, 1)$ cell is really big or small. $\{7, 8, 9\}$ in the $(1, 1)$ cell are all more extreme than the observed in one direction. $\{3, 2, 1, 0\}$ are as extreme or more than the observed in the other direction.
The other benefit of the particular table structure is that we can easily work out the exact probability of each configuration. In our example, we have two independent samples, one from each method. Each behaves as a binomial with the appropriate number of trials ($m = 9$, $n = 10$) and probability $\frac{1}{2}$ of being above or below the common median under $H_0$.
But they are also conditional on the fixed row totals, which are also binomial - the number of trials is $m + n = 19$. So, for our particular configuration, the probability is:
$$ \frac{\binom{9}{6}0.5^9 \cdot \binom{10}{3}0.5^{10}}{\binom{19}{9}0.5^{19}} = \frac{\binom{9}{6} \binom{10}{3}}{\binom{19}{9}} \Rightarrow \text{prob. for observed configuration}\ $$
We need to compute this type of probability for all the more extreme tables mentioned above, and add them all up.
In general, with two independent samples of sizes $m$ and $n$; with $r$ values above the combined sample median in the first sample, and no sample values are equal to the combined sample median (just for ease of notation as clearly we can do the computation), the probability of that table configuration is
$$ \begin{aligned} \frac{\binom{m}{r} \binom{n}{k-r}}{\binom{m+n}{k}}, \quad k = \frac{m+n}{2} \end{aligned} $$
Two-sample distribution tests
We can also extend the tests for a single sample’s distribution. We’d like to ask if it’s reasonable to assume that two samples of data come from the same distribution. Note that we haven’t specified which distribution.
The Kolmogorov-Smirnov test
The test to use is called the Smirnov or K-S test. Our hypotheses are
$$ \begin{aligned} &H_0: \text{the two samples come from the same distribution} \\ \text{vs. } &H_1: \text{the distributions are different} \end{aligned} $$
This is inherently a two-sided alternative. One-sided alternatives exist, but are very rarely used. Recall that in the one sample case, we compared our empirical CDF from the data with the CDF of the distribution hypothesized under $H_0$. In this more general case, we will now compare the two CDFs. The test statistic is the difference of greatest magnitude between the two.
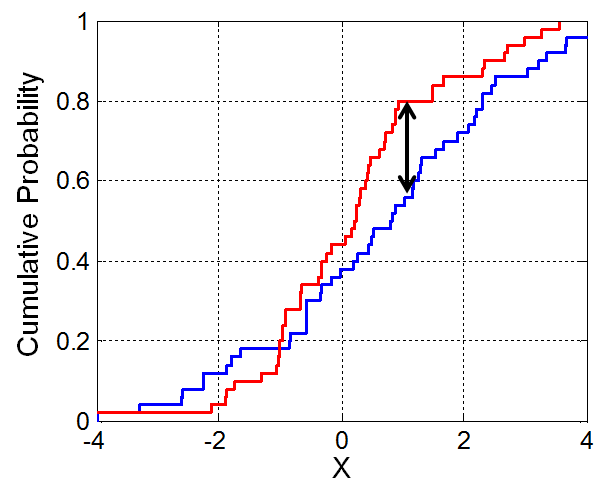
As before, this is taken as the vertical distance between empirical CDFs. A simplified version would look like the table below, where we record the distance between the empirical distribution function of the two samples.
| Ranked Observation | $S_1(x)$ | $S_2(y)$ | $K$ |
|---|---|---|---|
| $x_1$ | $\frac{1}{3}$ | $0$ | $\frac{1}{3}$ |
| $x_2$ | $\frac{2}{3}$ | $0$ | $\frac{2}{3}^\ast$ |
| $y_1$ | $\frac{2}{3}$ | $\frac{1}{2}$ | $\frac{1}{6}$ |
| $x_3$ | $1$ | $\frac{1}{2}$ | $\frac{1}{2}$ |
| $y_2$ | $1$ | $1$ | $0$ |
The K-S test is a test for general or overall difference in distributions. You can get a more sensitive analysis with a specific test for particular characteristics, if that is your goal (test for difference in means, differences in variance, etc.)
In R, we use the ks.test() as in the one-sample case. By default, the option exact = NULL is used. An exact p-value is computed if $m \times n < 10000$. There are also asymptotic approximation which will be used for even larger samples.
Interestingly, the K-S statistic depends only on the order of the $x$ and $y$s in the ordered combined sample - the actual numerical values are not needed, because empirical CDFs jump at data points. Under standard two-sided tests, all orderings are equally likely, so the exact distribution of the test statistic can be known for the given sample sizes using just the ranks.
Cramer-von Mises test
The Cramer-von Mises test is another test which examines whether two samples of data come from the same distribution. The difference is that it looks at all the differences $S_1(x) - S_2(y)$, where $S_1(\cdot)$ is the empirical CDF of sample 1, and $S_2(\cdot)$ is the empirical CDF of sample 2. These values are evaluated at all $(x, y)$ pairs.
The test statistic is:
\[T = \frac{mn}{(m+n)^2}\sum_{x, y} \left[S_1(x) - S_2(y) \right]^2\]
Similarly, this test is only used for a two-sided alternative. Values of $T$ have been tabulated and there is an approximation that is not strongly dependent on sample size. The exact null distribution can be found, as for other tests, by considering all ordered arrangements of the combined sample to be equally likely, and by computing $T$ for each ordered arrangement.
Note that ties won’t affect the results unless the sample sizes are really small. Usually the tests assume by nature there’s a true ordering.
| May 08 | Modern Nonparametric Regression | 8 min read |
| May 06 | Bootstrap | 11 min read |
| May 06 | Categorical Data | 17 min read |
| May 06 | Density Estimation | 6 min read |
| May 05 | Correlation and Concordance | 9 min read |